How Can Companies Utilise Random Forest algorithm to make Smart Predictions

I. Introduction
Random Forest is a flexible, easy to use machine learning algorithm that produces, even without hyper-parameter tuning, a great result most of the time. It is also one of the most used algorithms, because of it’s simplicity and the fact that it can be used for both classification and regression tasks. In this blog, I will explain the concepts of Random Forest Algorithm and applications of the algorithm.
II. Concepts of Random Forest algorithm
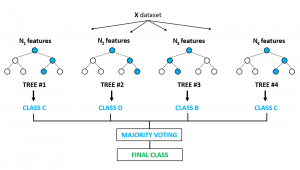
Random Forest is a supervised learning algorithm. As mentioned in the name, it creates a forest and makes it somehow random. The forest it builds, is an ensemble of Decision Trees, most of the time trained with the bagging method. The general idea of the bagging method is that a combination of learning models increases the overall result. One big advantage of random forest is, that it can be used for both classification and regression problems, which form the majority of current machine learning systems.
Basically, a random forest creates many individual decision trees working on important variables with a certain data set applied. One key factor is that in a random forest, the data set and variable analysis of each decision tree will typically overlap. That’s important to the model, because the random forest model takes the average results for each decision tree, and factors them into a weighted decision. In essence, the analysis is taking all of the votes of various decision trees and building a consensus to offer productive and logical results.
Application of Random Forest:
- Banking – Fraud Detection
- Stock Markets – Understanding Stock Behaviours
- Medicine – Disease Identification
- E-Commerce – Predict a customer purchasing a product or not
III. Conclusion
Random Forest is a great algorithm to train early in the model development process, because of its simplicity. This algorithm is also a great choice, if you need to develop a model in a short period of time. On top of that, it provides a pretty good indicator of the importance it assigns to your features. Random Forests are also very hard to beat in terms of performance. Also, they can handle a lot of different feature types, like binary, categorical and numerical. Overall, Random Forest is a fast, simple and flexible tool having it’s own limitation.
