Predict Future outcomes using Decision Trees

Introduction
With the increase in the implementation of Machine Learning algorithms for solving industrial needs, the demand for simple and accurate algorithms has increased. Decision trees are one of the simplest and oldest techniques used for problem solving.
What is a decision tree?
A decision tree is a graphical representation of all the possible solutions to a decision-based problem with more than one conditions; it is called a decision tree because it starts with a root-like representation, which then branches off into a number of solutions, just like a tree, and predicts the decisions. It is also called if-then classifier.
It is different from other algorithms because it works intuitively by taking the decisions one by one and commits to a decision, if a particular input satisfies all the conditions at each level.
Why decision tree
The main requirement of machine learning is to automate the decision-making process when input is fed. Decision trees are used for the following reasons:
- They are used to solve a variety of problems by making decisions at different levels.
- They are easy to understand & implement and are easily interpretable.
- Unlike most Machine Learning algorithms, they work effectively with non-linear data.
How does it work?
- Select the feature that best classifies the data set into the desired classes and assign that feature to the root node.
- Traverse down from the root node, whilst making relevant decisions at each internal node such that each internal node best classifies the data.
- Route back to step 1 and repeat until you assign a class to the input data.
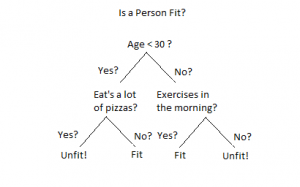
Let’s say we are given a data of 1000 people and are asked to report how many of them are fit and how many are unfit .
From the data given, we will first try to pick the important parameters that can be used to distinguish a fit and an unfit person. Let’s say we have collected keywords like AGE, EATING HABITS, EXERCISE HABITS, etc. Then we will build the conditions for a person to get classified as fit or unfit. For a person to be fit, let’s assume that a person’s age should be less than 30. Then we check whether he/she has good eating and exercise habits and then conclude whether he/she is fit or unfit.
In the same way, the algorithm looks at the base condition and, based on how the input satisfies the condition, the decision-making proceeds to other levels until the desired output is found.
Conclusion
Decision trees are very simple and easy to interpret. They can help us understand the strength of and relationship between attributes. Decision trees work with both categorical & numerical features and can handle missing values.
