Effective Decision Making using Decision Trees

I. Overview of Decision Trees
Decision Trees is a type of Supervised Algorithm, which uses a tree structure to specify sequences of decisions and consequences, for a given input X, the goal of the decision trees is to predict a response or output variable Y. Each member of the set {X} is called an input variable. The prediction can be achieved by constructing a decision tree with test points and branches. Due to it’s flexibility and easy visualization, decision trees are commonly used in data mining applications for classification purposes.
Decision trees have two varieties: Classification Trees [Supervised] and Regression Trees. Classification Trees are used to apply to output variables that are categorical in nature, whereas, Regression Trees are used to apply to output variables that are numeric or continuous.
II. Example Use-Case
Decision Tree usually breaks down the data-set into smaller subsets with increase in depth of the tree, the final output consists of a Decision Node and a Leaf Node;
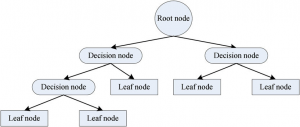
- Root Node – It represents entire population or sample and this further gets divided into two or more homogeneous sets.
- Decision Node – When a sub-node splits into further sub-nodes, then it is called decision node.
- Leaf Node – Nodes with no children or no further split.
In order to understand in simpler terms, let us consider an example: Let’s say that you are hired to build a predictive model for a resort which is considering a big advertisement campaign. The concept of the campaign is to send out 1000 vouchers which provides a one night stay at the resort free of cost to potential clients with a hope that they will extend their stay.
To come with a list of 1000 potential client names you are provided with a extensive database of customer data, including fields such as where they are from, income range, earlier stay duration, money spent, marital status, no of occupants, employment status and others. You would like to create a decision tree to help select the customers to send the vouchers to (specifically, those who will spend more and stay for more than a day.
The output of the model will basically be categorical such as Yes or No, In order to arrive at the model the computer will perform the following steps;
- From the above list of customer data, find the property that best separates the customers into two groups.
- Repeat step one for each of the above groups using the remaining properties.
- In the end, you will have a tree where at each point, you can make one of two decisions. Following a path leads to a decision. The split points will be chosen to maximize the probability of a correct classification.
Other possible applications of Decision Trees are;
- Demand Fulfillment
- Decision making on when to launch new products
- Decision on Product Endorsement
- Customer Relationship Management
III. Conclusion
Decision trees assist analysts in evaluating upcoming choices. The tree creates a visual representation of all possible outcomes, rewards and follow-up decisions in one document. Each subsequent decision resulting from the original choice is also depicted on the tree, so you can see the overall effect of any one decision. As you go through the tree and make choices, you will see a specific path from one node to another and the impact a decision made now could have down the road.
