Matching Words Which are Similar Phonetically – Fuzzy Logic

Introduction
Fuzzy Logic:
Fuzzy matching is a method that provides an improved ability to process word-based matching queries to find matching phrases or sentences from a database. When an exact match is not found for a sentence or phrase, fuzzy matching can be applied.
Fuzzy matching attempts to find a match which, although not a 100 percent match, is above the threshold matching percentage set by the application.
It works with matches that may be less than 100% perfect when finding correspondences between segments of a text and entries in a database of previous translations.
Business Situation
Customer having the practitioner’s prescription for the patient’s diagnosis and diseases in a text file, collected from the various hospitals and data has entered manually. Now the problem is to map the practitioner prescribed diagnosis details with the International Statistical Classification of Diseases and Related Health Problems (ICD).
Diseases are classified with ICD-10 code; that code should have mapped with practitioner’s prescribed diagnosis.
Here the challenges are customer’s data are not aligned in right format and the diagnosis information varies for each practitioner.
Objective is, practitioner prescribed diagnosis information should closely match with International Statistical Classification of Diseases to map the ICD-10 code.
Solution
Pentaho provides the solution for the above business case using PDI. With the help of Pentaho we can analyze the text file and process the semi-structured data to match with structured data.
To increase match relevance we shall use the SOLR and OpenNLP techniques for the better search.
How PDI works for Fuzzy match
Pentaho data integration supports fuzzy match method. The Fuzzy Match step finds strings that potentially match using duplicate-detecting algorithms that calculate the similarity of two streams of data.
This step returns matching values as a separated list as specified by user-defined minimal or maximal values.
The below Algorithms are used in Pentaho Fuzzy match step. Within the Algorithm field, there are several options available to compare and match strings.
- Levenshtein and Damerau-Levenshtein—calculate the distance between two strings by looking at how many edit steps are needed to get from one string to another. The former only looks at inserts, deletes, and replacements. The latter adds transposition. The score indicates the minimum number of changes needed. For instance, the difference between John and Jan would be two; to turn the name John into Jan you need one step to replace the O with an A, and another step to delete the H.
- Needleman Wunsch—calculates the similarity of two sequences and is mainly used in bioinformatics. The algorithm calculates a gap penalty. The aforementioned example would have a score of negative two.
- Jaro and Jaro Winkler—calculate a similarity index between two strings. The result is a fraction between zero, indicating no similarity, and one, indicating an identical match.

- Pair letters similarity—dissects the two strings in pairs and calculates the similarity of the two strings by dividing the number of common pairs by the sum of the pairs from both strings.
Metaphone, Double Metaphone, SoundEx, and Refined SoundEx—are phonetic algorithms, which try to match strings based on how they would sound. Each is based on the English language and would not be useful to compare other languages.
- The Metaphone algorithm returns an encoded value based on the English pronunciation of a given word. The encoded value of the names John and Jan would return the value JN for both names.
- The Double Metaphone algorithm has fundamental design improvements over its predecessor and uses a more complex rule set for coding. It can return a primary and a secondary encoded value for a string. The names John and Jan each return Metaphone key values of JN and AN.
- The Soundex algorithm returns a single encoded value for a name that consists of a letter followed by three numerical digits. The letter is the first letter of the name, and the digits encode the remaining consonants.
- The Refined SoundEx algorithm is an improvement over its predecessor. Encoded values for this algorithm are six digits long, the initial character is encoded, and multiple possible encodings can be returned for a single name. Using this algorithm, the name John returns the values 160000 and 460000, as does the name Jan.
Process Flow in PDI:
To extract/map the relevant data from the structured data for the semi-structured data, we used to follow the below steps
Step 1: wi Transform the semi structured data into structured data using respective transform steps from PDI

Step 2: Match the practitioner prescribed diagnosis with Master Diagnosis to fetch the respective ICD code
Step 3: Use the fuzzy match step to achieve the process, there we have to choose the right algorithm to do the fuzzy match process.
Jaro Winkler algorithm will fetch maximum relevant strings from master with score value
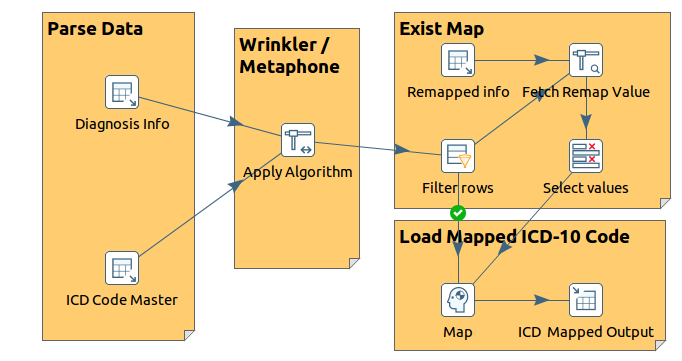
Step 4: Store the mapped/matched value into table with score value which is used to determine the matched sentence accuracy

User Interface to Edit / Remap the ICD:
Pentaho UI supports the customized table editor, which helps to update or remap the mapped the ICD code to the respective diagnosis.
User can search the Diagnosis based on ICD code or ICD code based on diagnosis respectively.
The below screenshot explains, how the interface can be used to update the matched records.

Summary
With the help of Pentaho fuzzy match process, customer’s semi-structure data was analyzed and processed to match the standard classification of diseases.
Customers are able to edit or remap ICD code for the respective diagnosis with the help of matching score value.

References:
Fuzzy match Step
:https://wiki.pentaho.com/display/EAI/Fuzzy+match
