Increasing the Performance of ML Algorithms using Boosting Techniques

I. Introduction
Boosting is an Machine Learning technique that is known for its predictive speed and accuracy. From data science competitions to business solutions, boosting has produced best-in-class results. Gradient boosting belongs to the group of machine learning techniques called ‘Ensemble Techniques’, which also includes the method known as bagging.
When we predict something using machine learning, at least one of the following errors occur;
- Noise (data that is irrelevant to the goal at hand)
- Variance (any extreme variation)
- Bias (happens when a sample drawn from a population is not representative of the whole population; this causes us to distrust the results)
Ensemble techniques help in reducing variance and bias and improve predictions. An ensemble is a collection of predictors that combine together to give a final prediction. It relies on the intuition that the next possible best model, when combined with previous models, minimises predictive errors. The next best model is called “strong learner”, while the previous models are called “weak learners”.
How does it Work?
A sequence of “weak learners” are created several times to get a succession of weak hypotheses, each one focusing on the errors of the previous weak learner. Decision trees are used to represent weak learners. The trees are created sequentially in such a way that each subsequent tree aims to reduce the errors of the previous tree.
II. Boosting Techniques
The different types of boosting algorithms are:
- AdaBoost
- Gradient Boosting
- XGBoost
These three algorithms have gained huge popularity, especially XGBoost. Let’s understand the concepts of these three algorithms;
AdaBoost (Adaptive Boosting)
AdaBoost combines multiple weak learners into a single strong learner. The weak learners in AdaBoost are decision trees with a single split, called decision stumps. When AdaBoost creates its first decision stump, all observations are weighted equally. To correct the previous error, the observations that were incorrectly classified now carry more weight than the observations that were correctly classified. AdaBoost algorithms can be used for both classification and regression problem.
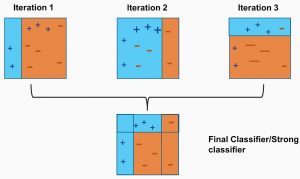
As we see above, the first decision block is made by separating the (+) blue region from the ( - ) red region. We notice that the decision block in Iteration One has three incorrectly classified (+) in the red region. The incorrect classified (+) will now carry more weight than the other observations and fed to the second learner. The model will continue and adjust the error faced by the previous model until the most accurate predictor is built.
Gradient Boosting
Just like AdaBoost, Gradient Boosting works by sequentially adding predictors to an ensemble, each one correcting its predecessor. However, instead of changing the weights for every incorrect classified observation at every iteration like AdaBoost, Gradient Boosting method tries to fit the new predictor to the residual errors made by the previous predictor.
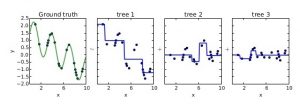
GBM uses Gradient Descent to find the shortcomings in the previous learner’s predictions. GBM algorithm can be given by following steps.
- Fit a model to the data, F1(x) = y
- Fit a model to the residuals, h1(x) = y−F1(x)
- Create a new model, F2(x) = F1(x) + h1(x)
- By combining weak learner after weak learner, our final model is able to account for a lot of the error from the original model and reduces this error over time.
XGBoost
XGBoost (eXtreme Gradient Boosting) is an advanced implementation of the gradient boosting algorithm. XGBoost has proved to be a highly effective ML algorithm, extensively used in machine learning competitions. XGBoost has high predictive power and is almost ten times faster than the other gradient boosting techniques. It also includes a variety of regularization which reduces over-fitting and improves overall performance. Hence it is also known as ‘Regularized Boosting‘ technique.
XGBoost is comparatively better than other techniques in the following ways:
- Regularization
- Standard GBM implementation has no regularization like XGBoost.
- Thus XGBoost also helps to reduce over-fitting.
- Parallel Processing
- XGBoost implements parallel processing and is faster than GBM .
- XGBoost also supports implementation on Hadoop.
- High Flexibility
- XGBoost allows users to define custom optimization objectives and evaluation criteria adding a whole new dimension to the model.
- Handling Missing Values
- XGBoost has an in-built routine to handle missing values.
- Tree Pruning
- XGBoost makes splits up to the max_depth specified and then starts pruning the tree backwards and removes splits beyond which there is no positive gain.
- Built-in Cross-Validation
- XGBoost allows a user to run a cross-validation at each iteration of the boosting process and thus it is easy to get the exact optimum number of boosting iterations in a single run.
III. Conclusion
In this blog, we have looked at Boosting, one of the method of ensemble modeling to enhance the prediction power. We have discussed about the concepts behind boosting and its three types: AdaBoost, Gradient Boost and XGBoost.
