Text Classification using Support Vector Machines

I. Introduction
Support vector machines are a type of supervised machine algorithm for learning which is used for classification and regression tasks. Though they are used for both classification and regression, they are mainly used for classification challenges. In this blog, we will go through the concepts of Support Vector Machine and it’s applications.
II. Concepts and Uses
Support Vector Algorithm is performed by plotting each acquired value of data as a point on an n-dimensional space or graph. Where “n” represents the total number of a feature of data that is present. The value of each data is represented as a particular coordinate on the graph. After distribution of coordinate data, we can perform classification by finding the line or hyper-plane that distinctly divides and differentiates between the two classes of data.
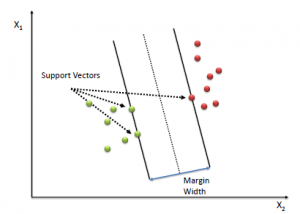
Support vectors are the data points nearest to the hyperplane, the points of a data set that, if removed, would alter the position of the dividing hyperplane. Because of this, they can be considered the critical elements of a data set. As a simple example, consider the image given above, for a classification task with only two features, you can think of a hyperplane as a line that linearly separates and classifies a set of data.
Intuitively, the further from the hyperplane our data points lie, the more confident we are that they have been correctly classified. We therefore want our data points to be as far away from the hyperplane as possible, while still being on the correct side of it.
Applications of Support Vector Machine:
- Text Classification
- Spam Detection
- Sentiment Analytics
- Image Recognition
- Postal Automation Services
III. Conclusion
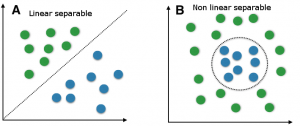
Support Vector Machine allows you to classify data that’s linearly separable. Compared to newer algorithms like neural networks, they have two main advantages: Higher Speed and Better Performance with a limited number of samples. This makes the algorithm very suitable for text classification problems.
